
《kafka权威指南》
第一章、初识Kafka
一个分布式的、可分区的、可复制的提交日志服务。
1.1 发布与订阅消息系统
传统的发布订阅消息系统
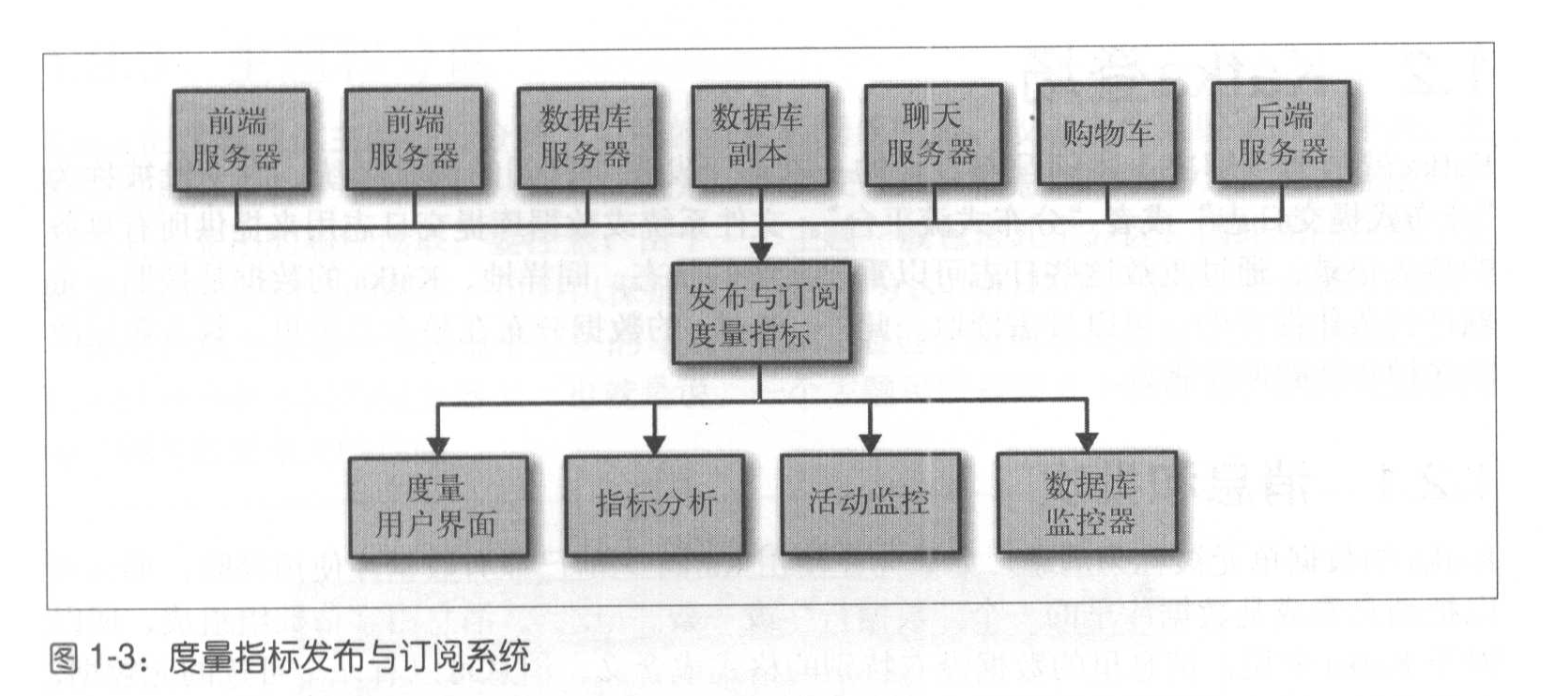
一个独立的应用程序,用于接收所有其他应用程序的指标,并为其他系统提供一个查询接口。
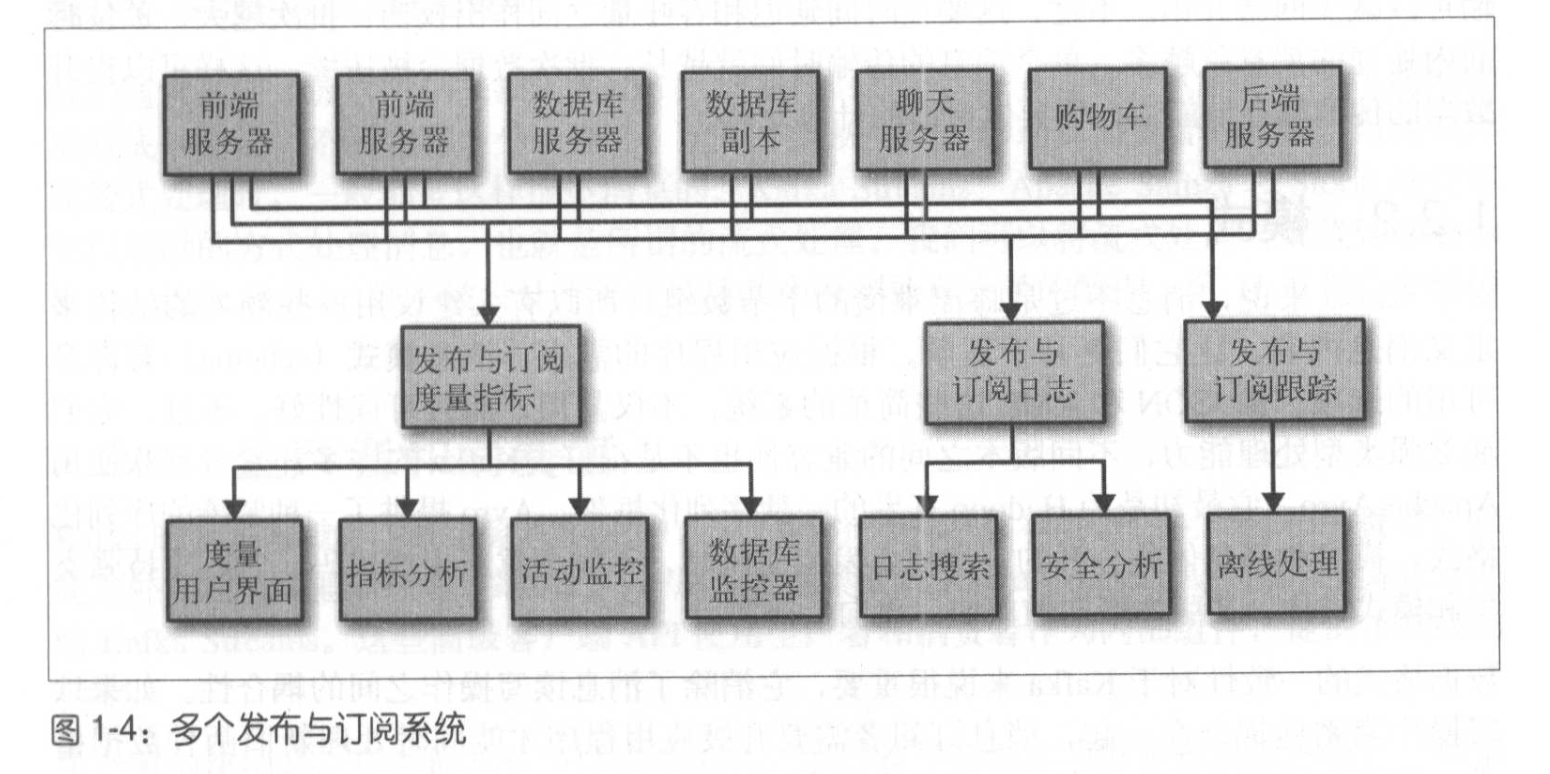
在传统发布订阅的基础上,增加发布与订阅日志和发布与订阅跟踪。这样又新增了2个独立的应用程序单独负责。
三个独立的应用程序,有太多重复的部分,且各自之间也存在缺陷和不足。所以需要一个单一的集中式系统的需求就应孕而生。(公司业务规模越大,此需求越大)
1.2 Kafka登场(简介)
kafka就是统一上面三个独立应用程序而创造的消息系统。一般被称为“分布式提交日志”或者“分布式流平台”。文件系统或数据库来提供所有事务的持久记录,通过重放日志可以重建系统的状态。Kafka的日志是按照顺序持久化保存的,可以按需读取。kafka的数据分布在整个传统里,具备数据故障保护和性能伸缩能力。
- 消息和批次
消息:
kafka的数据单元被称为消息,类似于mysql中的数行或一条记录。消息由byte数组组成,消息里的数据没有特别的格式和含义。消息可以有一个可选的元数据(key),key也是一个字节数组,和消息一样没有格式和特殊含义。消息根据key存入一个一致性散列值(hash表),根据散列值把消息存入不同的分区。这样可以保证具有相同key的消息总被分配到相同的分区上。
批次:
为了提高效率,消息被分批次写入kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果消息不按照批次处理,大量消息将导致网络开销巨大。不过批次越大,单位时间内处理的消息就越多,单个消息传输的时间就越长。(吞吐量越大,时间延迟越高) 批次内的消息会被压缩。
- 主题和分区
kafka的消息通过主题进行分类,主题就好比数据库的表。一个主题可以被分为若干个分区,一个消息就是一个提交日志,消息以追加的方式写入分区,然后以先入先出的顺序读取。一个主题一般包含多个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证单个分区内的顺序。 每个分区可以分布在不同的服务器上,一个主题可以横跨多个服务器,以此来提供更强大的性能。
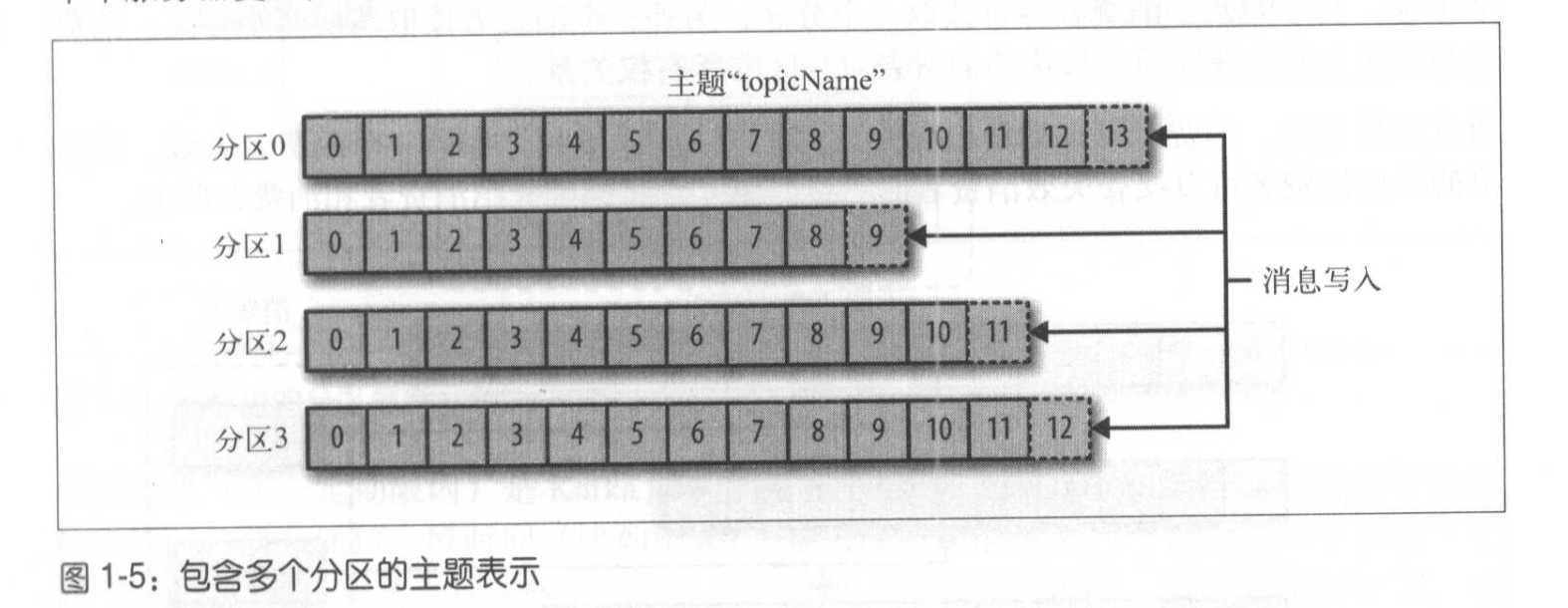
流指一组从生产者移动到消费者的数据。框架以实时的方式处理消息,也就是所谓的流式处理。
- 生产者和消费者
生产者创建消息,生产者把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。(消息会根据key来决定会被分布到哪个分区)
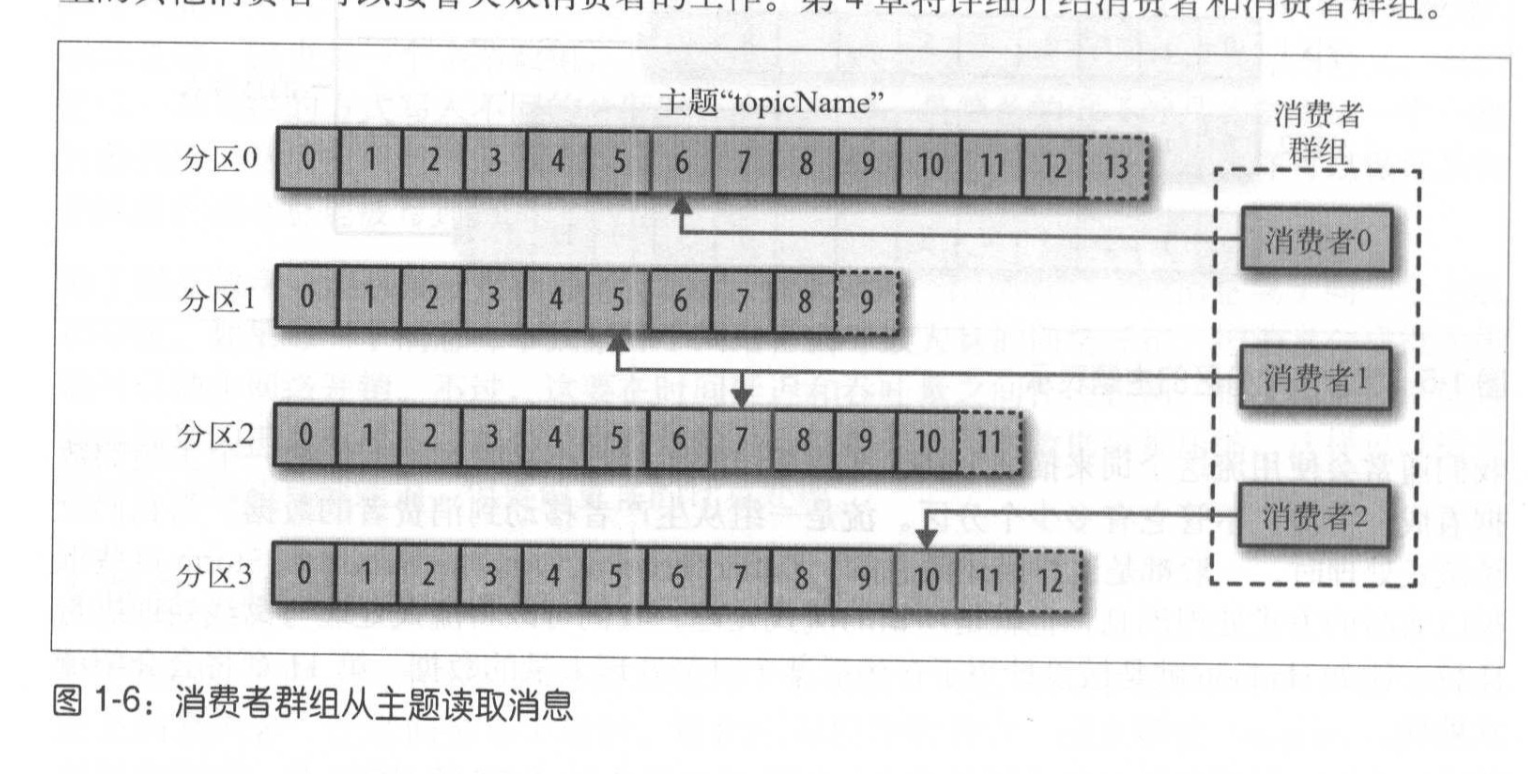
消费者读取消息,消费者订阅一个或多个主题,并按照消息生成的顺序读取他们,消费者通过偏移量来确定消息是否已经读取过。偏移量是一个不断递增的元数据,在消息被创建时,kafka会把它添加到消息里,在给定的分区内,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的偏移量保存在ZooKeeper或者kafka上,如果消费者服务器重启,它的读取状态不会丢失。
- broker和集群
一个独立的kafka服务器被称为 broker,broker接收来自生产者的消息,为消息设置偏移量,并把消息保存到磁盘。broker为消费者提供服务,对读取分区的请求做出响应。
broker是 集群的组成部分,每个集群都有一个broker同时充当集群控制器的角色(leader)。控制器负责管理工作,包括将分区分配给broker和监视broker。一个分区可以被分配给一个或多个broker,(分区复制)。这种复制机制为分区提供了消息冗余,如果一个broker失效,其他broker可以接管。不过相关的生产者消费者要连接到新的接管broker上。
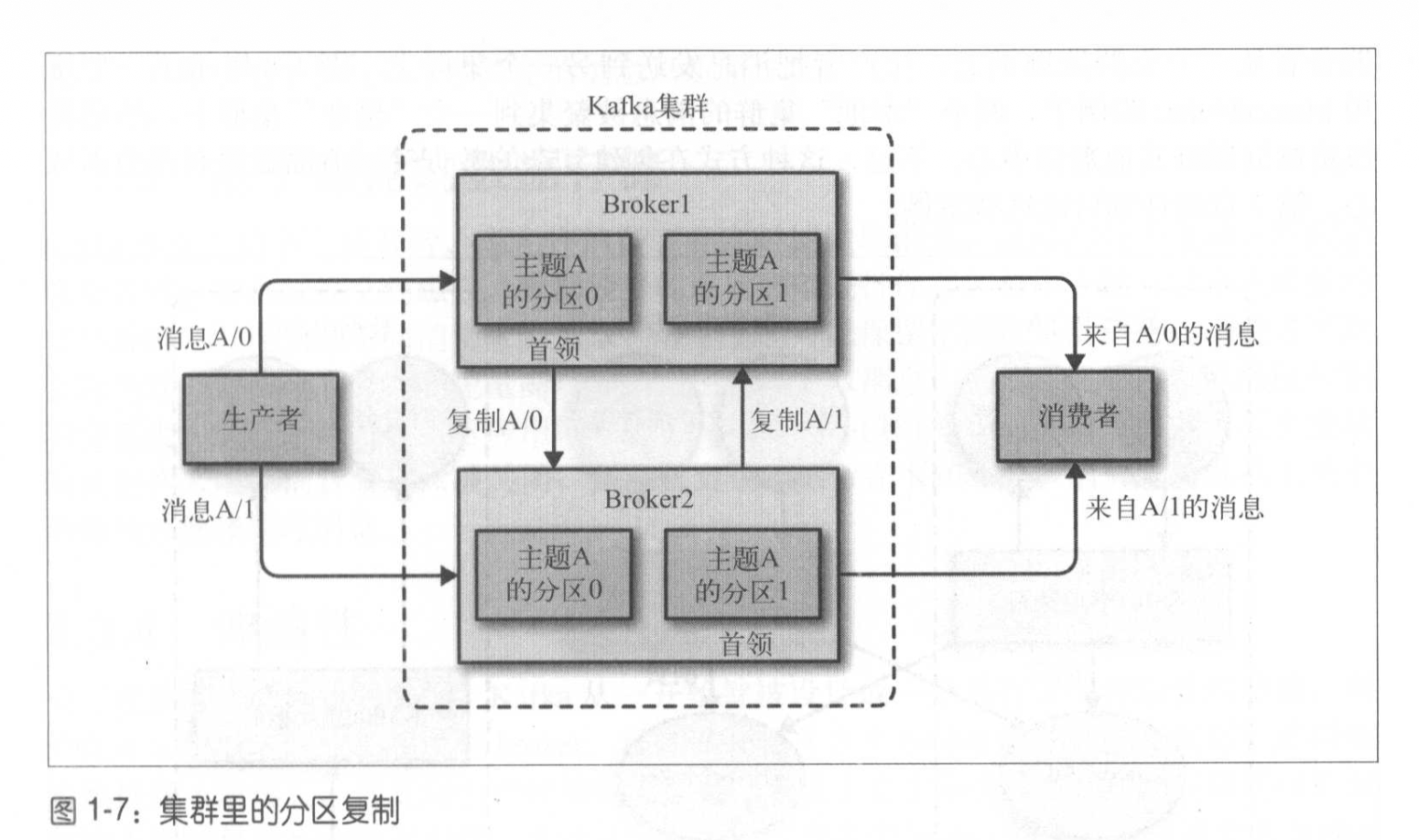
消息保留,kafka可以保留一段时间(7天)或者保留到消息达到一定大小的字节数(1GB)。当消息达到上限时,旧的消息会过期并删除。
- 多集群
如果kafka数量众多,可以基于一下几点原因,使用多个集群。
数据类型分离、安全需求隔离、多数据中心(灾备)
如果使用了多个集群,则需要在它们之间复制消息。这样才可以保证应用程序可以多个站点中访问到相同的数据。kafka基于broker的消息复制机制,只能在单个集群中进行。 为了让消息在多个集群间复制,kafka提供了一个叫做MirrorMaker的工具。
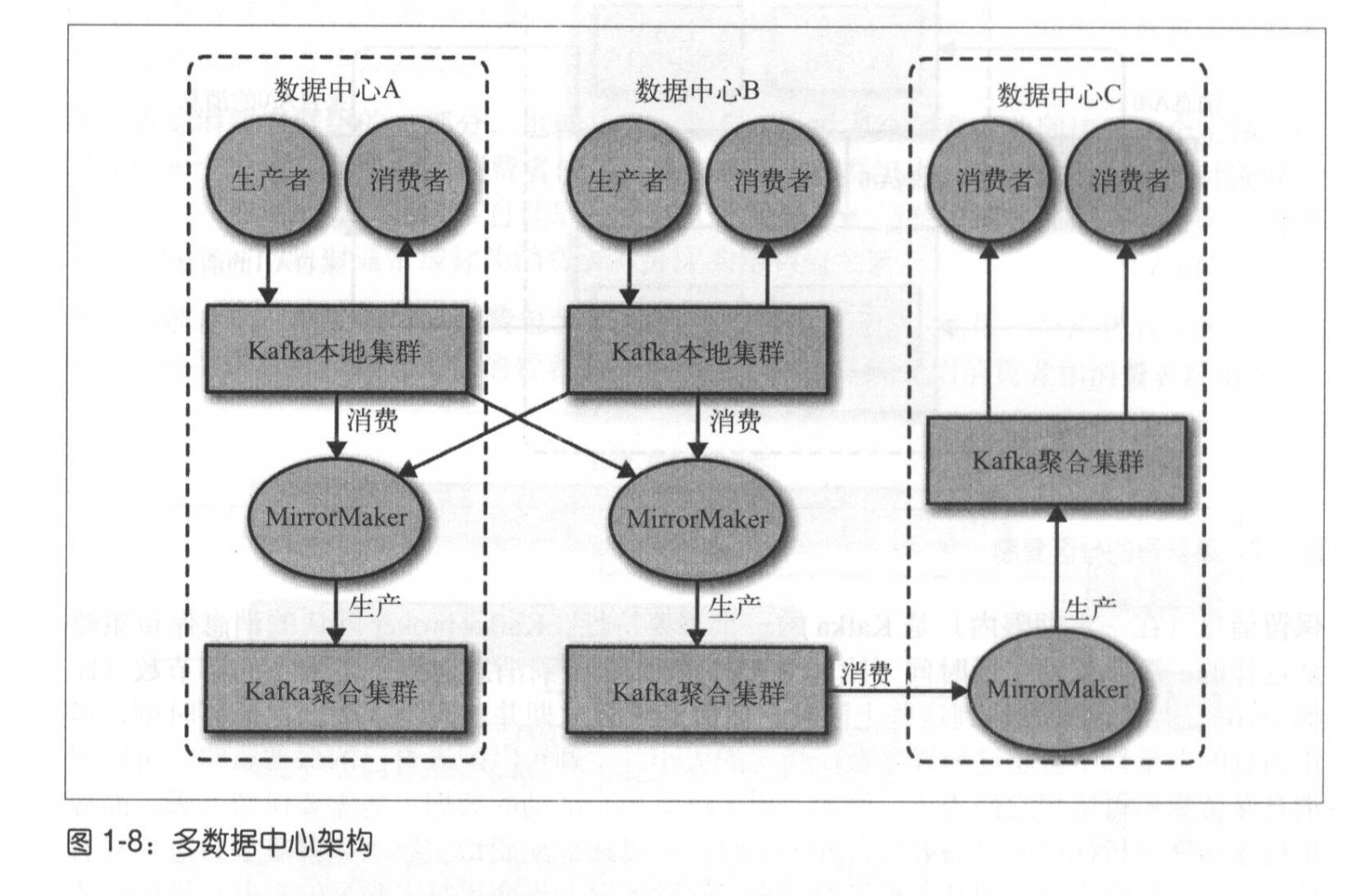
中心A生产者发布一个消息到中心A,中心B中的mirrorMaker读取中心A中的消息,传递给中心C中的mirrorMaker,中心C的maker把消息发布到中心C中。
1.3 Why kafka
kafka的优势
- 多生产者:可以同时接收多个生产者产生的数据,帮助统一格式。
- 多消费者:可已让多个消费者组成一个群组,保证每个群组一个消息只被处理一次(同一个消息被多个消费者处理)
- 基于磁盘的数据存储:消息被提交到磁盘,可以有效的错峰,或灾备。
- 伸缩性:kafka是一个灵活伸缩的系统,可以随着业务的发展来动态调整kafka应用数量。
- 高性能:kafka可以轻松处理巨大的消息流,可以保证亚秒级的消息延迟。
第三章、向kafka写入数据(生产者)
生产者概览
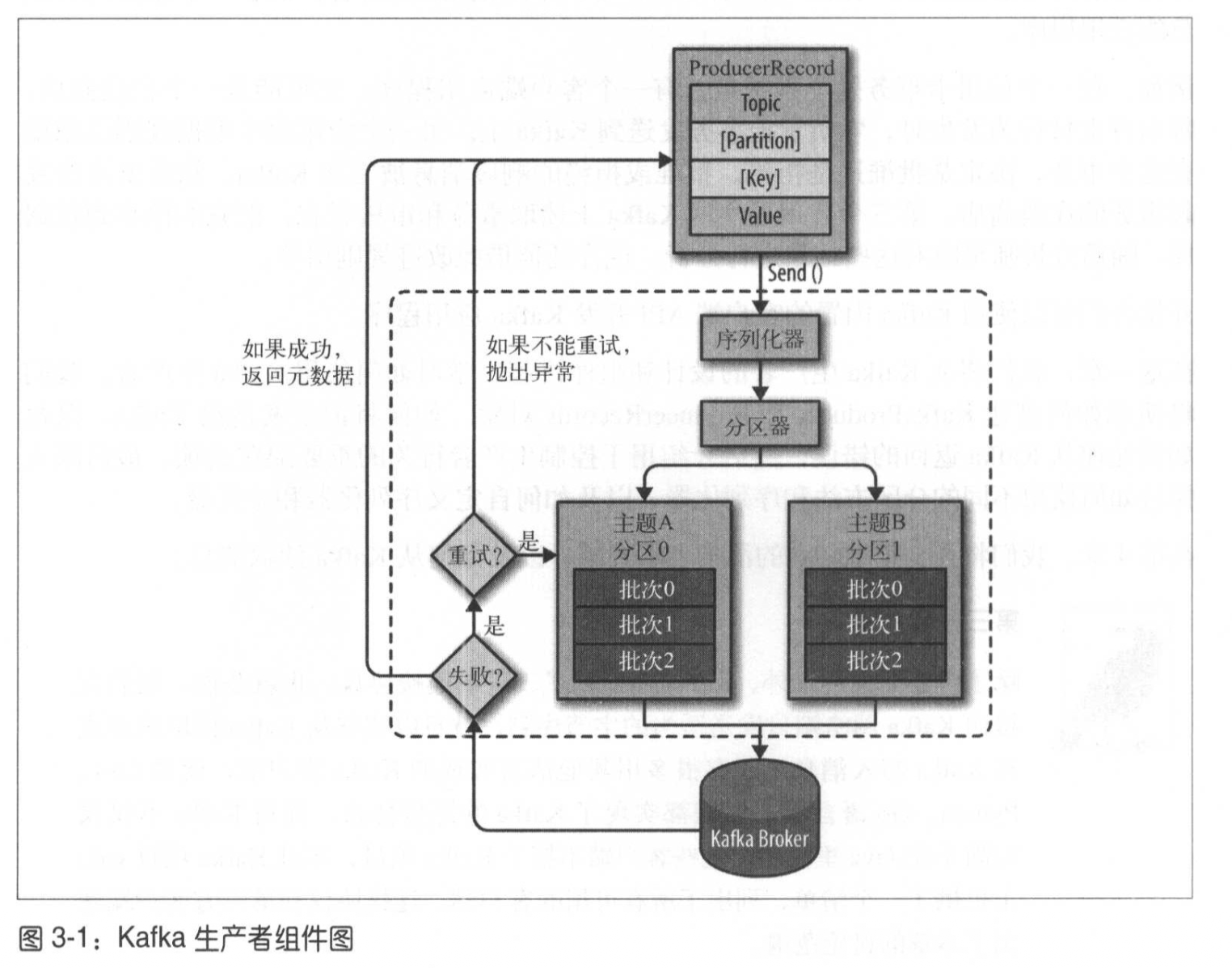
- 生产者先创建一个ProducerRecord对象,对象中包含目标主题,发送的内容。(同时可以指定键或分区)在发送对象时,生产者把键和值序列化成字节数组。
- 数据被传递给分区器,如果之前ProducerRecord对象指定了分区,分区器不会做任何事;如果没有,分区器会根据ProducerRecord对象的键来选择一个分区。选择好分区后,生产者可以得知该往哪个主题的哪个分区发送这条记录。此记录会被添加到一个记录批次里,这个批次里的所有消息都会被发送到相同的主题和分区上。(一个单独的线程负责把这些记录批次发送到相应的broker上)
- 服务器在收到消息后。如果消息成功写入kafka,就返回包含主题和分区信息的响应对象,以及记录在分区里的偏移量。如果写入失败就返回一个报错。生产者可以时情况重试或者失败。
发送消息到kafka
- 发送并忘记(fire-and-forget)
把消息发送到服务器,并不关心是否正常到达。因为kafka是高可用的,而且生产者会自动尝试重发,但还有可能会丢失一部份消息。
- 同步发送
使用send()方法后,会返回一个Future对象,调用get()方法进行等待,可以得知消息是否发送成功。
- 异步发送
使用send()方法时,指定一个回调函数,服务器在返回响应时调用该函数。
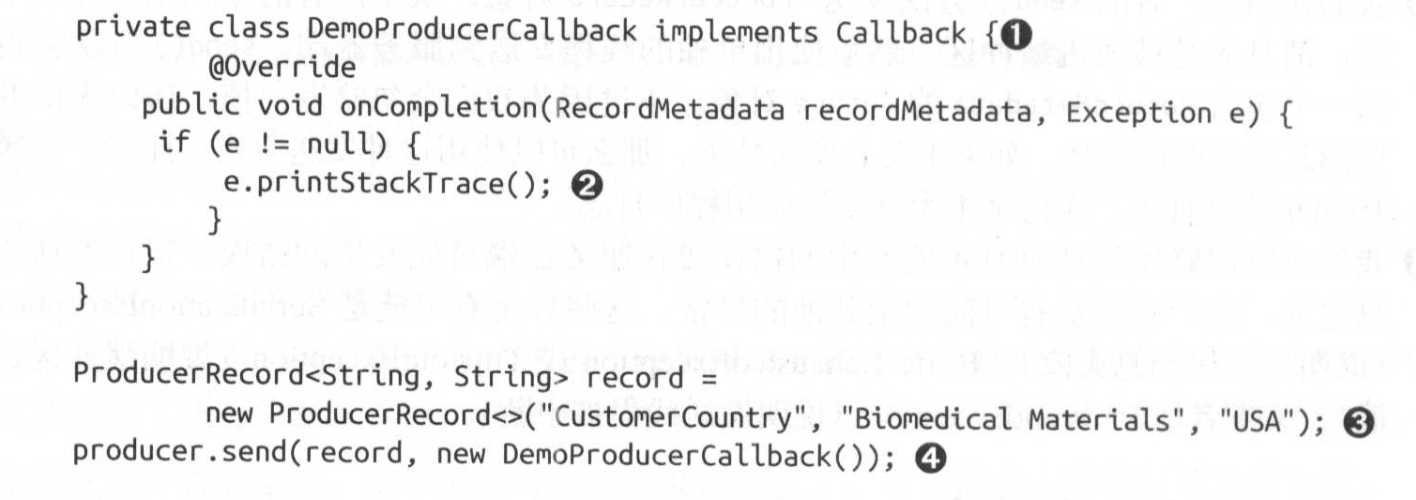
结果返回时,会调用Demo类中的onCompletion方法
生产者配置
- acks
指定有多少个分区副本收到消息,生产者才会认为消息写入成功。
acks=0:生产者不会等待任何来自服务器的响应。(如果中间出现了问题,生产者无从得知,消息也会丢失)发送消息速度最快,吞吐量大
acks=1:只要集群的首领节点收到消息,生产者就会收到来自服务器的成功响应。如果消息无法到达首领节点,生产者会收到一个错误响应,并重试。在重试期间,如果集群选出了一个新的首领。会时新首领有没有收到消息的情况来判断消息是否会丢失。(收到就不丢失,没收到则丢失)由于存在消息重试,如果是同步发送消息模式,则可能会影响性能和吞吐量
acks=All:所有参与复制的节点都收到消息时,生产者才会收到一个服务器的成功响应。此模式最安全,它可以保证就算所有服务器都发生了崩溃,整个集群仍可以正常运行。吞吐量最差,最安全
第四章、从kafka读取数据(消费者)
kafkaConsumer概念
kafka可以视消息生产消费的速度,来动态的调整同一主题下,消息的生产者和消费者数量。(多个生产者向同一个主题写入消息,多个消费者从同一个主题中读取消息)
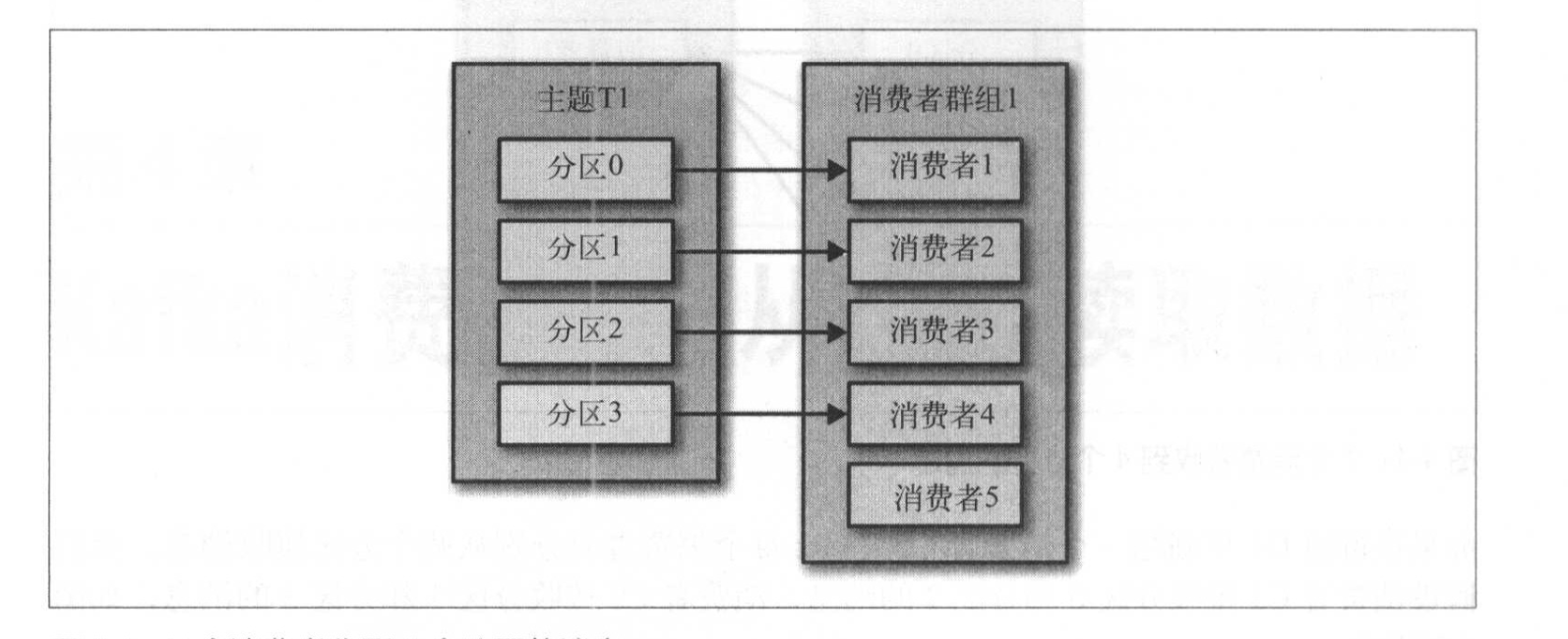
一个分区只能给同一消费者群组中的一个消费来消费。多个分区可以同时给一个消费者消费。如果同一消费者群体中,消费者大于分区数,则会导致一个消费者闲置
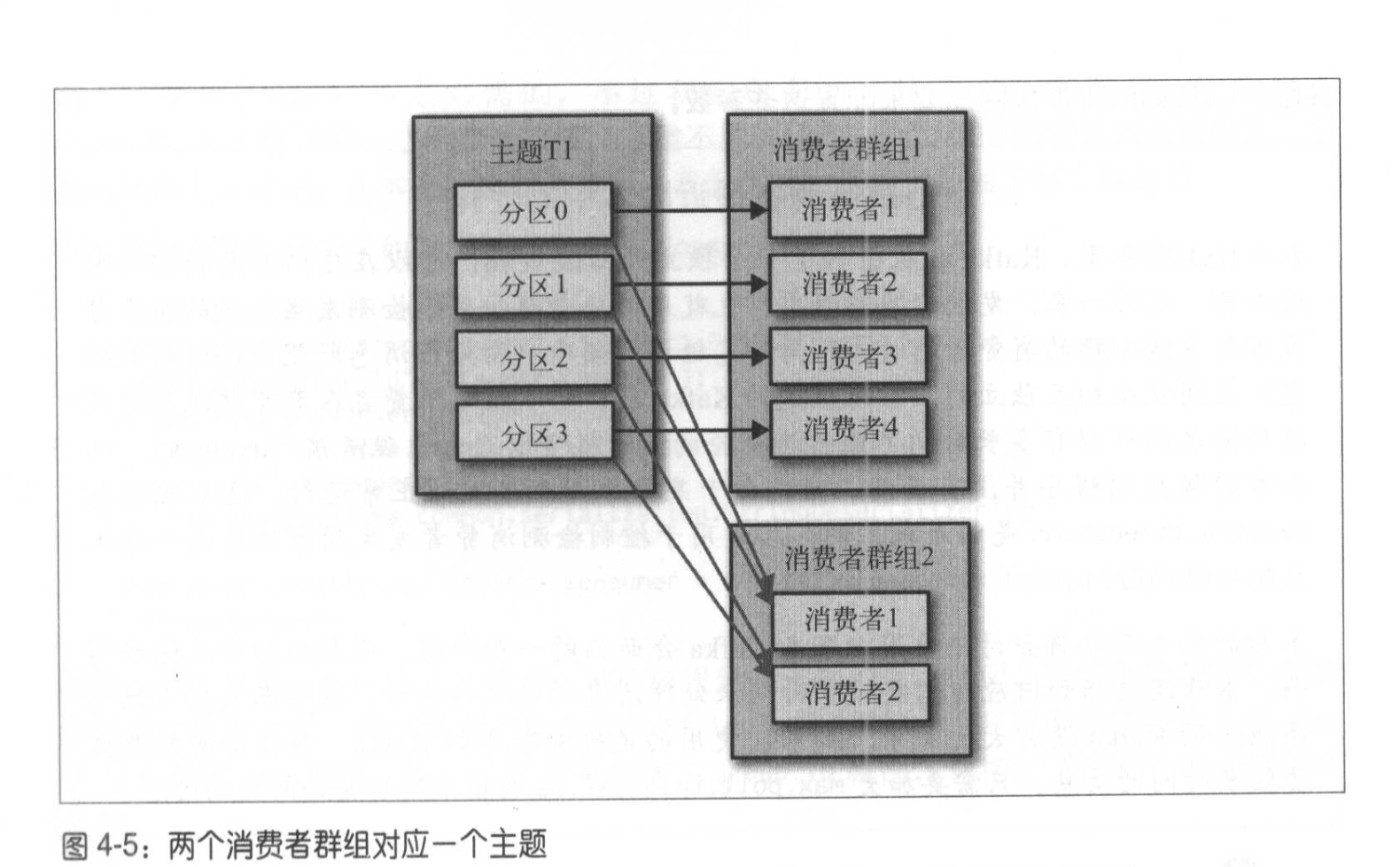
两个消费者群体读取同一主题的消息,两个消费者群体互不影响(相互隔离)
提交和偏移量
消费者每次调用poll()方法,会返回由生产者写入但没有被消费者读取过的记录。
消费者向_consumer_offerSet的特殊主题发送消息,消息中包含每个分区的偏移量。如果消费者发生崩溃,或者有新的消费者加入群组,就会发生 再均衡,每个消费者可能会被分配到新的分区,而不是之前处理的那个。消费者根据偏移量来获取每个分区最后一次提交的偏移量,然后从偏移量指定的地方继续消费。
- 提交的偏移量小于客户端处理的最后一个消息的偏移量:导致消息被重复消费
- 提交的偏移量大于客户端处理的最后一个消息的偏移量:导致消息丢失。
消息的几种提交方式:
- 自动提交
处理方便,但可能会导致重复消费
每隔一段时候(默认5s),消费者自动把最大的偏移量提交。
如果在最后一次提交的3s后发生了再均衡,新的消费者从最后一次提交的偏移量开始读取消息,会导致在这3s内到达的消息被重复消费。
- 提交当期偏移量(同步)
开发者自定义,消息重复程度视每次提交间隔的数据
由开发者自己控制偏移量的提交,通过commitSync()方法主动提交。(返回结果前,会阻塞程序)
如果在主动提交之前程序崩溃,会导致上次提交前的消息都被重复消费。
- 异步提交偏移量
开发者自定义,无重试,只会异步发送一次提交,不管提交是否成功。
还是开发者自己控制提交偏移量操作,通过commitAsync()方法。但提交线程不会等待返回结果,直接继续执行。
需要注意,因为异步可能会产生各种延迟问题。可能后发先至,先发后至。开发者应在回调时,自己维护目前最大偏移量,避免出现较小偏移量覆盖较大偏移量的情况。
- 同步和异步组合提交
同步提交速度慢,但可靠。异步提交速度快,但可能会出现问题。程序正常运行时,可采用异步提交,就算某次提交失败,也可以在下次提交时,记录最新偏移量。
程序关闭,或最后一次提交时,应严格采用同步提交。保证偏移量的最终准确性。
- 提交特定的偏移量
上述提交的方式,都是按照“整批”为维度来提交偏移量的。如果一个批次很大,但消费者想在处理到一半时提交偏移量。就需要使用提交本地map的方式来处理。
| |
第五章、深入kafka
分区和节点管理
- 如何注册和退出
kafka通过订阅ZooKeeper的/brokers/ids路径下的节点来管理broker的加入集群或者退出集群。(ZooKeeper当做kafka的注册中心)
- 如何选择集群leader
成为leader:集群里的每个broker都会尝试在ZooKeeper目录下创建一个临时节点/controller,只会有一个成功, 其他的创建失败。
重新选举:通过ZooKeeper的watch机制,当发现之前leader节点下线后,每个broker都会尝试在ZooKeeper中创建临时节点/controller来让自己当选leader。
离群分区分配:上面成为leader的broker发现某个分区的broker离开了集群,leader的broker会遍历这些分区,并选出一个新的broker来消费当前分区。
kafka通过ZooKeeper的临时节点来选举控制器,并在节点加入集群或退出集群时通知控制器。控制器负责在节点加入或离开集群时进行分区首领选举。控制器通过版本号来避免脑裂
复制
在个别节点失效时,仍能保证kafka的可用性和持久性。
- 主从复制
首领副本:每个分区的主副本,所有生产者和消费者请求都会经过这个副本。
跟随者副本:首领副本之外的都是跟随者副本,跟随者副本不处理用户请求,只从首领副本复制消息。(在首领部分失效后,成为新的首领副本)
- 同步状态检测
首领副本下线后,只有 同步的跟随者副本才有可能被选择为新的首领副本。
进度:跟随者副本通过偏移量来向首领副本复制消息,这些偏移量都是有序获取的(1、2、3、4.。。)首领副本通过获取的偏移量,可以得知每个跟随者复制的进度。
超时:如果跟随者副本10秒内没有请求任何消息,则被认为是不同步的。不同步的跟随者不能成为新的首领。
请求处理
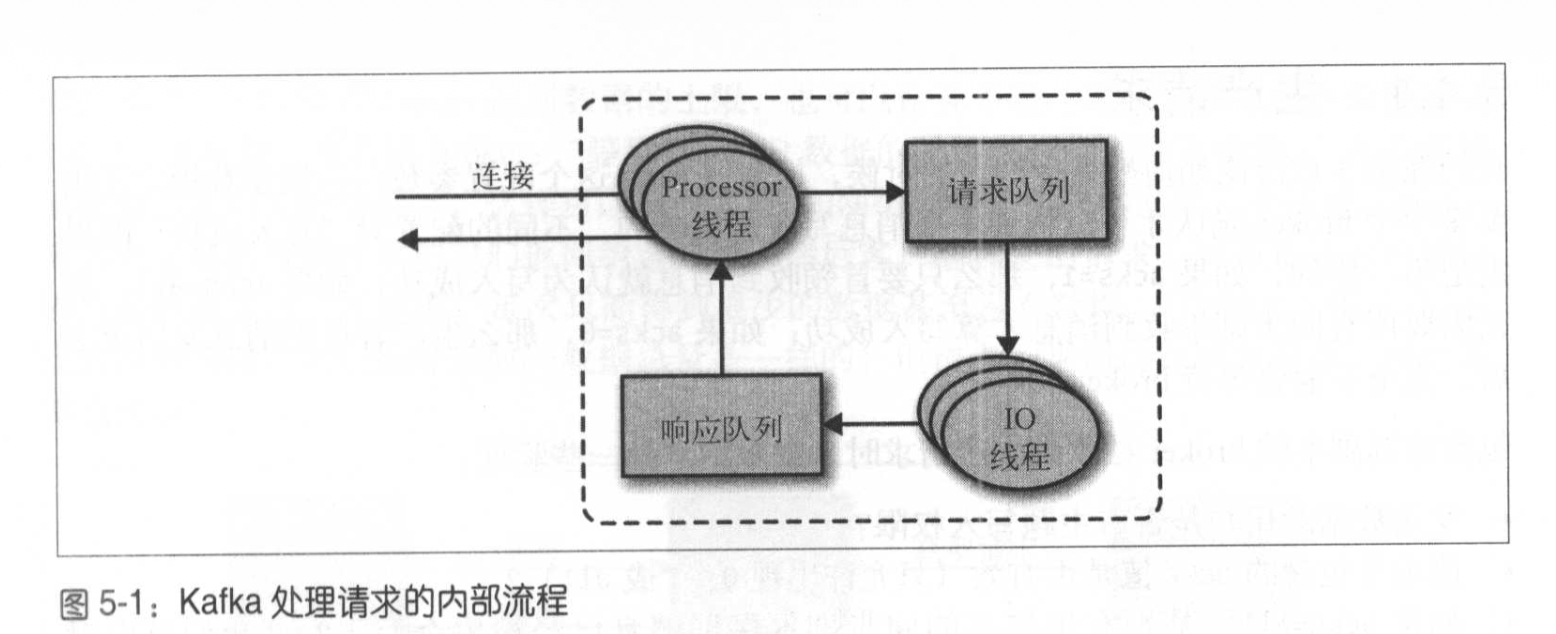
生产请求和获取请求(生产者和消费者)都必须发送请求给分区的首领副本,如果broker收到的特定分区的请求,而该分区的首领在另一个broker上,则broker会返回一个非分区首领的错误响应。
客户端需要自己负责把请求发送到正确的broker上。
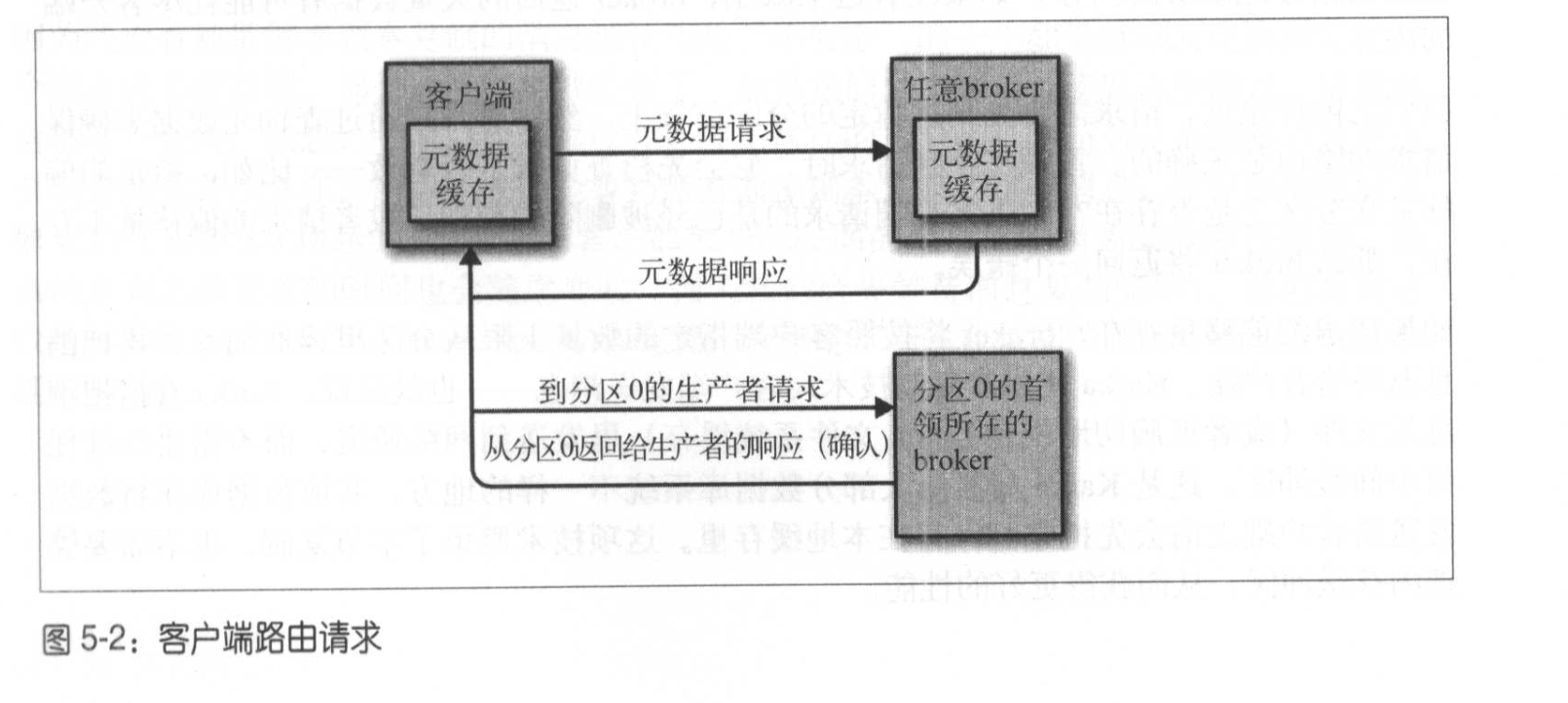
客户端通过元数据请求获取最新的分区请求,把不同分区的请求发送给正确的broker。
- 生产请求
首领副本的broker收到生产请求后:
- 发送数据的用户是否有主题的写入权限
- 请求中的acks值是否有效(0、1、all)
- 如果acks=all,判断是否有足够多的同步副本保证消息已经被安全写入
acks为0或1时:broker会立刻返回响应
acks=all:请求被保存在缓冲区(炼狱),知道首领副本发现所有跟随者副本都复制了消息,才把响应返回给客户端。
- 获取请求
kafka的broker使用零拷贝技术向客户端发送消息,kafka直接把消息从文件(Linux文件系统缓存)里发送到网络通道,不需要经过任何中间缓冲区。
避免了字节复制,也不需要管理内存缓冲区,从而获得更好的性能。
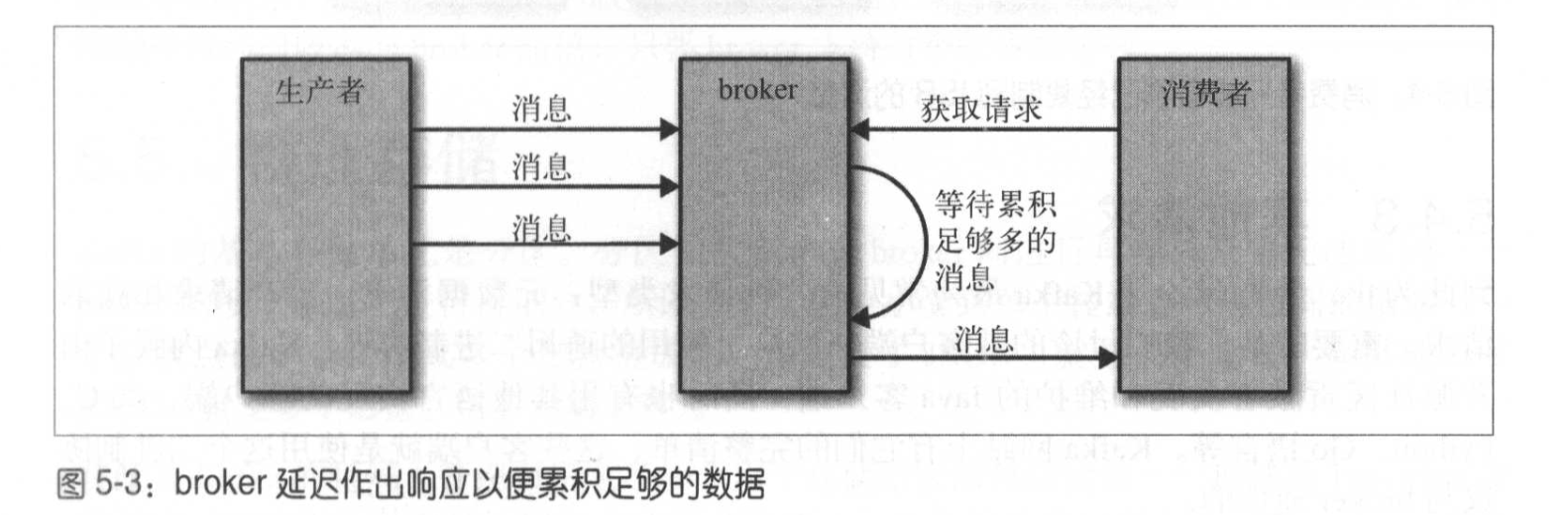
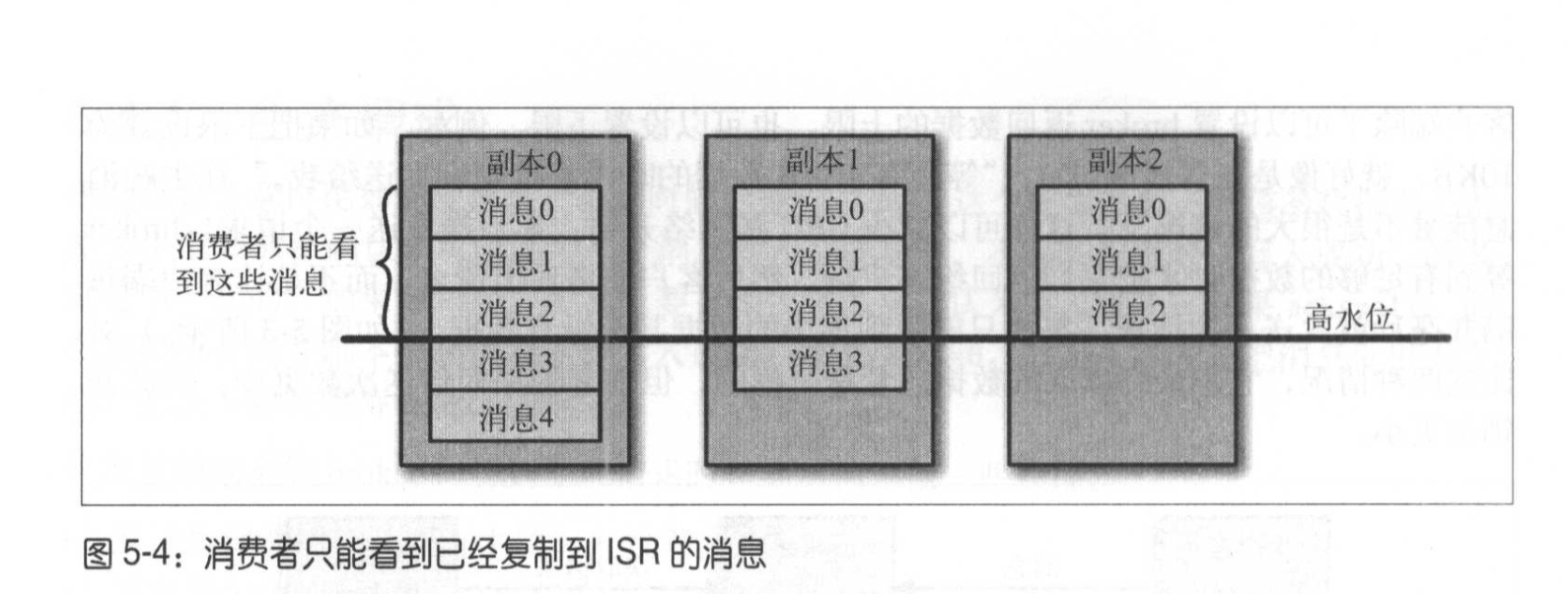
分区领主只会给消费者返回已经同步过的消息,还没有完全同步的消息会被认为时不安全的。
数据存储
- 分区分配
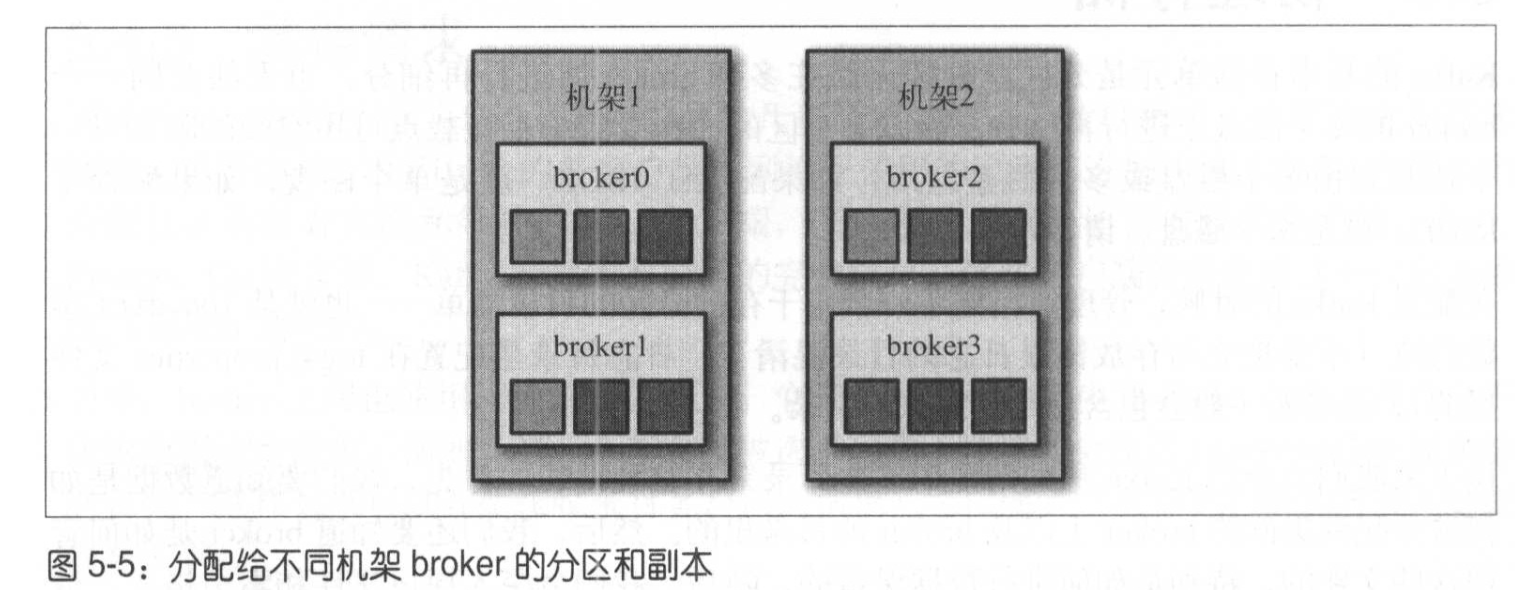
- kafka会在broker间平均的分布分区副本。
- kafka会确保每个分区的每个副本分布在不同的broker上。(为了保证高可用)
kafka在存储消息时,直接按照返回给消费者的格式来存储。(这样才能利用CPU零拷贝技术)

第六章、可靠的数据传递
可靠性保证
**保证:**确保系统在各种不同的环境下能够发生一致的行为。一致性
ACID是关系型数据库普遍支持的标准可靠性保证。
如果一个供应商说他们的数据库遵循 原子性、一致性、隔离性和持久性规范,其实就是说他的数据库支持与事务相关的行为。
- kafka可以保证分区消息的顺序。先写入的消息一定先被读到。
- 只有消息被写入分区的所有同步副本时(不一定是写入磁盘时),此消息才会被认为是“已提交”。(原子性)
- 只要有一个副本是活跃的,那么已经提交的消息就不会被丢失。(高可用)
- 消费者只能读取已提交的事务。(隔离性的表现)
以上几个机制可以用来构建可靠的系统,但仅依赖他们不能保证系统的完全可靠。
broker配置
管理员可以通过broker配置,来让主题变成可靠的或非可靠的。
- 复制系数
每个分区应该有多少个不同的broker了保存副本。
系数越高,系统越可靠。但性能消耗和空间也会成几何倍数增长。
如果系数为1:下线后只能等原broker上线才能使用系统。
如果系数为2:理论系统仍可正常提供服务,但一个broker出现问题,可能会导致另一个broker也需要重启,可能仍不能一致提供服务。
因此,默认推荐复制系数为3。保证一个broker下线后,系统仍能正常提供服务。
- 不完全的首领选举
分区首领下线后,默认会让一个 完全同步过的副本上线,但如果所有副本都不是完全同步的,则会触发不完全选举。
如果允许不完全同步选举,随可以保证系统可用,但可能会丢失部分消息。
如果不允许不完全同步选举,分区需等待原首领上线后才能提供服务,无法保证系统可用。
- 最少同步副本
决定一个消息需要同步到几个副本上,就认为消息被提交了。推荐为3个。如果过少,会导致分区不可用。(在可用性和一致性之间做决策)
可靠的生产者
- 发送确认
acks=0:生产这发送消息,就认为消息写入成功。性能最好,但可能会丢失消息。只要此过程中分区发生了选举,就一定会丢失消息。
acks=1:只要分区首领接收到了消息,就认为写入成功。为了保证消息可靠,需要在生产者添加消息重试机制。如果此次发生选举,仍可能会丢失部分消息。如分区首领在向分区副本同步时下线。相对丢失消息数量少。
acks=ALL:所有副本同步,才算收到消息。同时生成者也需要添加消息重试机制,性能最差,但最保险。
可靠的消费者(如何提交偏移量)
为了达到可靠的目标,如何提交偏移量可以让出问题的影响最小。
- 总是在处理完成事件后再提交偏移量
在一批次处理结束后提交(自动提交或者手动提交)偏移量。
可能会导致一批次数据的错误,需要做好事务,如果提交时系统宕机,则导致批次数据被重复消费。
- 提交操作报错后重试
由于kafka的消息是按照顺序排好的,如果一批次读取到30和31两条数据,30处理失败,31处理成功。如果只提交31偏移量,会让其他消费者认为31之前的数据全部处理成功。
对于上述场景,有两种处理方式:
提交最后一个处理成功的偏移量(31),把没有处理好的消息保存到缓冲区中(30),调用消费者的pause()方法让其他的轮询不返回数据,然后尝试30的消息,知道重试成功。成功后调用resume()方法,让消费者继续获取新数据。
暂停现有消费,先提交处理进度,最大努力重试失败的交易。如果系统宕机,可以从缓冲中获取到失败的交易,继续重试。
把错误写入一个独立的kafka主题,然后继续。由一个独立的消费者负责记录错误的主题,最大努力重试。(dead-letter-queue)
dead-letter-queue 死信队列:把错误或失败的数据,单独记录,不影响主流程的正常工作。但对于状态机等依赖前置状态的操作不可用。
- 消费者需根据处理进度维护状态 (记忆化搜索)
对于根据处理情况,来维护或统计状态的情况,要在上述处理后提交偏移量的基础上,并把每次处理的新状态写入一个单独的主题,让状态和偏移量对应。这样系统也方便重启或者从某个节点续跑。(有点类似于大数据的拉链表)
存在一个问题,就是kafka两个主题的提交并不存在事务,可能会导致一个主题提交成功,偏移量主题出错。所以要考虑两者的提交顺序。
- 长时间任务处理
如果有一个耗时长久的任务,会阻塞消费者线程,导致客户端长时间不能向broker发送心跳,broker可能会任务当前消费者下线。
建议使用一个线程池来处理任务,就算任务线程被阻塞,也会一直有线程轮询broker(但不获取新任务)。这样可以保持心跳。
- 保证消息仅被消费一次(幂等性)
利用第三方键值存储引擎,每次消费kafka消息时,生成唯一的键存入。
第七章、构建数据管道
构建数据管道时需要考虑的问题(kafka的优势)
- 及时性
对于消息kafka充当了一个超大型的缓冲区
实时处理:消费者可以通过轮询broker的方式,达到接近实时的数据处理。
批处理:消费者可以向kafka发送请求来读取自定义批次大小的数据。(可视业务情况动态调整)
- 可靠性
系统可靠性: kafka的高可用可以有效的避免单点故障问题,而且动态扩容分区副本,可以让kafka集群达到大规模的高可用。
消息可靠性:写入时有同步写入或回调,可以保证写入的可靠性。消费者需要配合唯一键值存储引擎来实现读取的可靠性。
- 高吞吐量和动态吞吐量
卡夫卡支持动态的伸缩,可以试情况动态的调整生产者和消费者的数量。如果处理不了的消息,也可以以极低的成本缓存在kafka中慢慢处理。
- 数据格式问题
kafka本身并不在意数据内容的格式,生产者和消费者可以使用各种不同的序列化器来进行格式转换。所以可以用kafka来实现各种跨不同格式系统的数据传输。
kafka Connect
为在kafka和外部数据存储系统之间移动数据提供了一种可靠且可伸缩的方式。
连接器
- 决定需要运行多少个任务
- 按照任务来拆分数据复制
- 从worker进程获取任务配置并将其传递下去。
任务
任务只把数据移出或移入kafka。
worker进程
worker进程是连接器和任务的”容器“。连接器和任务负责”数据的移动“,worker进程负责REST API、配置管理、可靠性、高可用性、伸缩性和负载均衡。