OceanBase调研
分区
OB可以把普通的表数据按照一定的规则划分到不同的区块内,同一区块的数据物理上存储在一起。
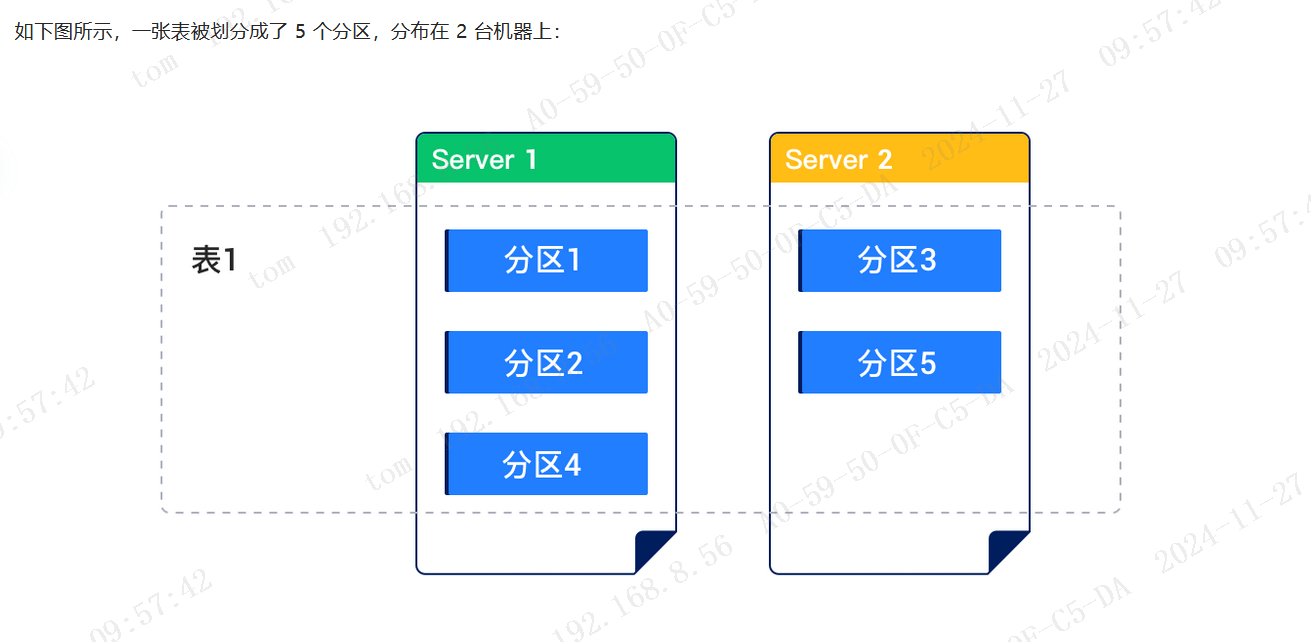
数据表中每一行中用于计算这一行属于哪一个分区的列的集合叫做分区键,分区键必须是主键或者唯一键的子集,只要有主键就必须是主键的子集。由分区键构成的用于计算这一行属于哪一个分区的表达式叫做分区表达式。
分区分类
Range分区
根据分区表定义时为每个分区建立的分区键值范围,将数据映射到相应的分区中。
例如:可以将业务日志表按日/周/月分区。
Range 分区的分区键必须是整数类型或 YEAR 类型,如果对其他类型的日期字段分区,则需要使用函数进行转换。Range 分区的分区键仅支持一列。
Range Columns 分区
Range Columns 分区与 Range 分区的作用基本类似,不同之处在于:
Range Columns 分区的分区键的结果不要求是整型,可以是以下数据类型:
支持所有整数类型,包括
TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)和BIGINT。支持的浮点类型,包括
DOUBLE、FLOAT和DECIMAL数据类型。具体类型包括:DECIMAL、DECIMAL[(M[,D])]DEC、NUMERIC、FIXEDFLOAT[(M,D)]、FLOAT(p)DOUBLE、DOUBLE[(M,D)]DOUBLE PRECISION、REAL
支持时间类型
DATE、DATETIME和TIMESTAMP。不支持使用其他与日期或时间相关数据类型的列作为分区键。
支持字符串类型 CHAR、 VARCHAR、 BINARY 和 VARBINARY。
不支持将 TEXT 或 BLOB 数据类型的列作为分区键。
Range Columns 分区的分区键不能使用表达式。
Range Columns 分区的分区键可以写多个列(即列向量)。
List 分区
List 分区使得您可以显式的控制记录行如何映射到分区,具体方法是为每个分区的分区键指定一组离散值列表,这点跟 Range 分区和 Hash 分区都不同。List 分区的优点是可以方便的对无序或无关的数据集进行分区。
List 分区的分区键可以是列名,也可以是一个表达式,分区键必须是整数类型或 YEAR 类型。
List Columns 分区
List Columns 分区与 List 分区的作用基本相同,不同之处在于:
List Columns 分区的分区键不要求是整型,可以是以下数据类型:
支持所有整数类型,包括 TINYINT、 SMALLINT、 MEDIUMINT、 INT ( INTEGER) 和 BIGINT。
不支持将其他数值数据类型(例如,DECIMAL 或 FLOAT)的列作为分区键。
支持时间类型 DATE 和 DATETIME。
不支持使用其他与日期或时间相关数据类型的列作为分区键。
支持字符串类型 CHAR、 VARCHAR、 BINARY 和 VARBINARY。
不支持将 TEXT 或 BLOB 数据类型的列作为分区键。
List Columns 分区的分区键不能使用表达式。
List Columns 分区支持多个分区键,List 分区仅支持单分区键。
Hash 分区
Hash 分区适合于对不能用 Range 分区、List 分区方法的场景,它的实现方法简单,通过对分区键上的 Hash 函数值来散列记录到不同分区中。如果您的数据符合下列特点,使用 Hash 分区是个很好的选择:
- 不能指定数据的分区键的列表特征。
- 不同范围内的数据大小相差非常大,并且很难手动调整均衡。
- 使用 Range 分区后数据聚集严重。
- 并行 DML、分区剪枝和分区连接等性能非常重要。
Hash 分区的分区键必须是整数类型或 YEAR 类型,并且可以使用表达式。
Key 分区
Key 分区与 Hash 分区类似,通过对分区键应用 Hash 算法后得到的整型值进行取模操作,从而确定数据应该属于哪个分区。
Key 分区有如下特点:
- Key 分区的分区键不要求为整型,可以为除 TEXT 和 BLOB 以外的其他数据类型。
- Key 分区的分区键不能使用表达式。
- Key 分区的分区键支持向量。
- Key 分区的分区键中不指定任何列时,表示 Key 分区的分区键是主键。
例:
| |
组合分区
组合分区通常是先使用一种分区策略,然后在子分区再使用另外一种分区策略,适合于业务表的数据量非常大时。使用组合分区能发挥多种分区策略的优点。
分区注意事项
在 MySQL 模式中,使用自增列作为分区键时,应注意以下事项:
- 在 OceanBase 数据库中,自增列的值全局唯一,但在分区内不保证递增。
- 与其他分区方式相比,对使用自增列作为分区键的分区表的插入操作由于无法有效路由,会产生跨机事务,性能会有一定的下降。
分区名字规则
对于 List 和 Range 分区,因为在创建表的过程中就指定了分区的名字,所以名字就是当时指定的名字。
对于 Hash/Key 分区,创建时如果没有指定分区的名字,分区的命名由系统根据命名规则完成。具体表现为:
- 当 Hash/Key 分区为一级分区时,则每个分区分别命名为 p0、p1、…、pn。
- 当 Hash/Key 分区为二级分区时,则每个分区分别命名为 sp0、sp1、 …、spn。
对于模板化二级分区表,定义二级分区后,系统根据二级分区的命名规则完成,其二级分区的命名规则为 ($part_name)s($subpart_name)。对于非模板化二级分区表,二级分区的分区名即为⾃定义的分区名。
创建和管理分区
创建不同类型的分区
分区分裂
将一个分区按照一定规则分成两个或者多个新分区的过程。一般发生在数据库中的大表中,以避免单个分区数据量过大,从而实现更好的数据管理和查询性能。
当前版本分区分裂功能为实验特性,暂不建议在生产环境使用。
手动分区
自动分区
分区裁剪
当用户访问分区表时,往往只需要访问其中的部分分区,通过优化器避免访问无关分区的优化过程我们称之为分区裁剪(Partition Pruning)。分区裁剪是分区表提供的重要优化手段,通过分区裁剪,SQL 的执行效率可以得到大幅度提升。您可以利用分区裁剪的特性,在访问中加入定位分区的条件,避免访问无关数据,优化查询性能。
分区裁剪就是根据 where 子句里面的条件并且计算得到分区列的值,然后通过结果判断需要访问哪些分区。如果分区条件为表达式,且该表达式作为一个整体出现在等值条件里,也可以做分区裁剪。
查询指定分区
如果 SQL 语句中指定了分区,系统会将查询的范围限定在所指定的分区集合内,同时根据 SQL 语句的查询条件进行分区裁剪。最终访问的分区为指定分区和分区裁剪二者的交集。
| |
索引
由于 OceanBase 数据库的表是索引组织表( IOT ),对于分区表而言,为了保证指定主键的查询能很快定位到表所在的分区,所以分区键必须是主键的子集。如果需要在分区表上创建局部分区唯一索引( Local Partitioned Unique Index ),则该索引键需要包含主表的分区键,而对于全局分区唯一索引( Global Partitioned Unique Index )并没有这个限制。
| |
局部索引
局部索引是针对单个分区上的数据创建的索引,因此局部索引的索引键值跟表中的数据是一一对应的关系,即局部索引上的一个分区一定对应到一个表分区,它们具有相同的分区规则,因此对于局部唯一索引而言,它只能保证分区内部的唯一性,而无法保证表数据的全局唯一性。
| |
如果在查询中,没有指定分区键,那么局部索引将无法进行分区裁剪,这时会扫描所有分区,增加额外的扫描代价。
全局索引
全局索引的创建规则是在索引属性中指定 GLOBAL 关键字。与局部索引相比,全局索引最大的特点是全局索引的分区规则跟表分区是相互独立的,全局索引允许指定自己的分区规则和分区个数,不一定需要跟表分区规则保持一致。
分布式执行和并行查询
分布式执行
OceanBase 数据库基于 Shared-Nothing 的分布式系统构建,具有分布式执行计划生成和执行能力。
由于一个关系数据表的数据会以分区的方式存放在系统里面的各个节点上,所以对于跨分区的数据查询请求,必然会要求执行计划能够对多个节点的数据进行操作。OceanBase 数据库的优化器会自动根据查询和数据的物理分布生成分布式执行计划。对于分布式执行计划,分区可以提高查询性能。如果数据库关系表比较小,则不必要进行分区,如果关系表比较大,则需要根据上层业务需求谨慎选择分区键,以保证大多数查询能够使用分区键进行分区裁剪,从而减少数据访问量。
并行查询
并行查询是指通过对查询计划的并行化执行,提升对每一个查询计划的 CPU 和 IO 处理能力,从而缩短单个查询的响应时间。并行查询技术可以用于分布式执行计划,也可以用于本地查询计划。
整体来说,并行查询的总体思路和分布式执行计划有相似之处,即将执行计划分解之后,将执行计划的每个部分由多个执行线程执行,通过一定的调度的方式,实现执行计划的 DFO 之间的并发执行和 DFO 内部的并发执行。
并行查询和分布式查询的原理
- 分布式数据库整体架构图
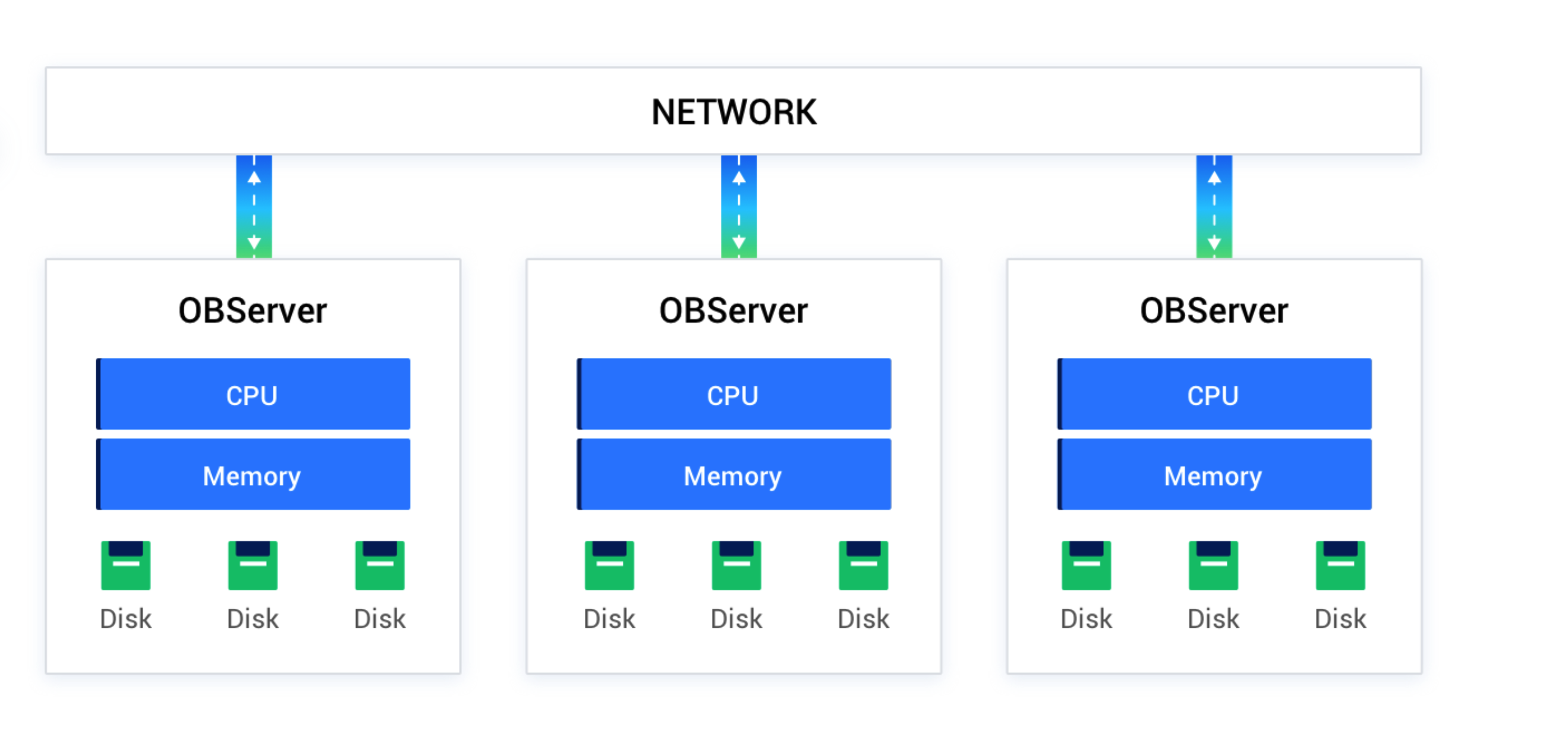
OceanBase 数据库的数据以分片的形式存储于每个节点,节点之间通过千兆、万兆网络通信。一般会在每个节点上部署一个叫做 observer 的进程,它是 OceanBase 数据库对外服务的主体。
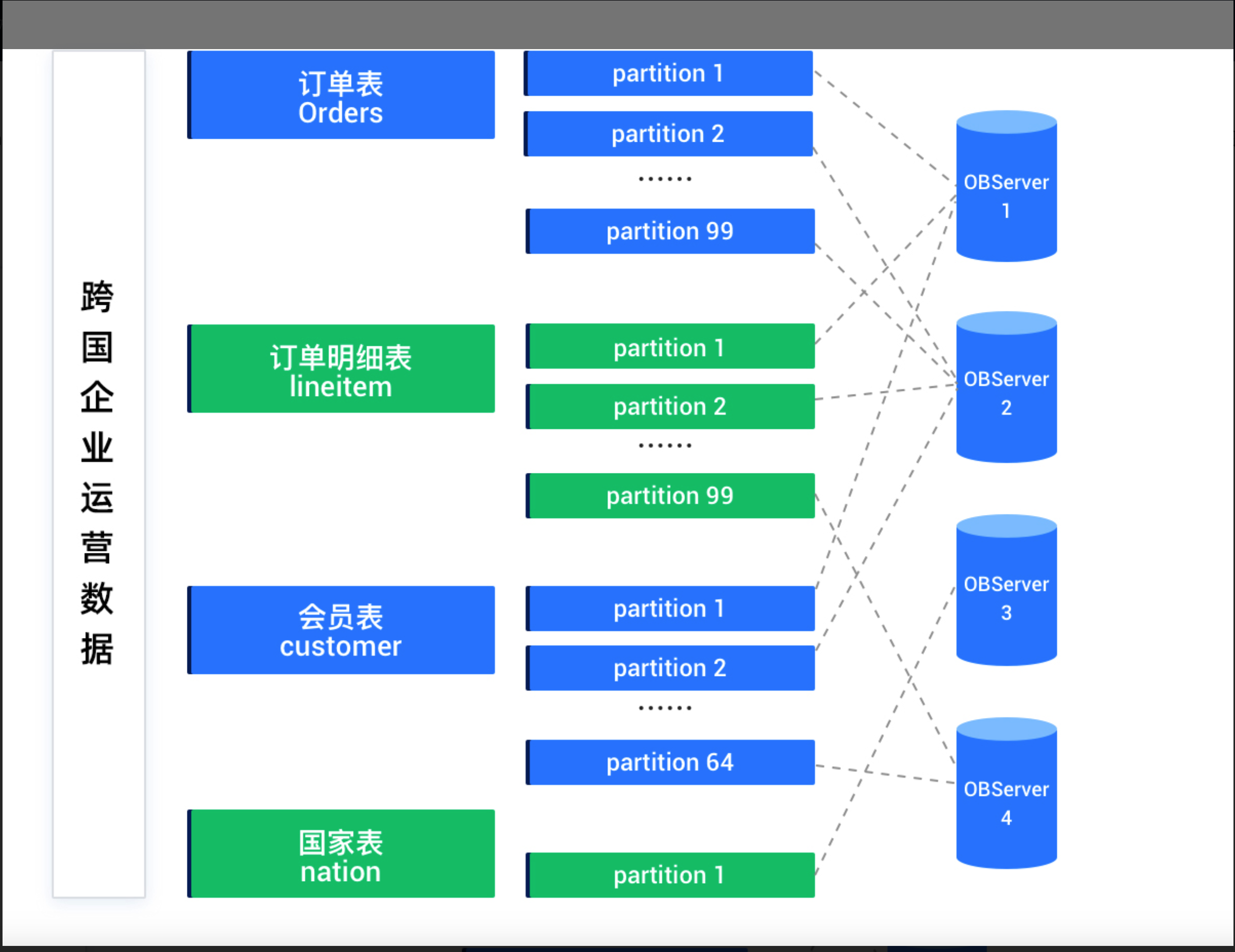
OceanBase 数据库会根据一定的均衡策略将数据分片均衡到多个 observer 进程上,因此对于一个并行查询一般需要同时访问多个 observer 进程。
并行执行流程
当用户指定的 SQL 语句需要访问的数据位于 2 台或 2 台以上 OBServer 节点时,就会启用并行执行,用户所连接的这个 OBServer 节点将承担查询协调者 QC(Query Coordinator)的角色,执行步骤如下:
- QC 预约足够的线程资源。
- QC 将需要并行的计划拆成多个子计划,即 DFO(Data Flow Operation)。每个 DFO 包含若干个串行执行的算子。例如,一个 DFO 里包含了扫描分区、聚集和发送算子的任务,另外一个 DFO 里包含了收集、聚集算子等任务。
- QC 按照一定的逻辑顺序将 DFO 调度到合适的 OBServer 节点上执行,OBServer 节点上会临时启动一个辅助协调者 SQC(Sub Query Coordinator),SQC 负责在所在 OBServer 节点上为各个 DFO 申请执行资源、构造执行上下文环境等,然后启动 DFO 在各个 OBServer 节点上进行并行执行。
- 当各个 DFO 都执行完毕,QC 会串行执行剩余部分的计算。例如,一个并行的
COUNT算法最终需要 QC 将各个机器上的计算结果做一个SUM运算。 - QC 所在线程将结果返回给客户端。
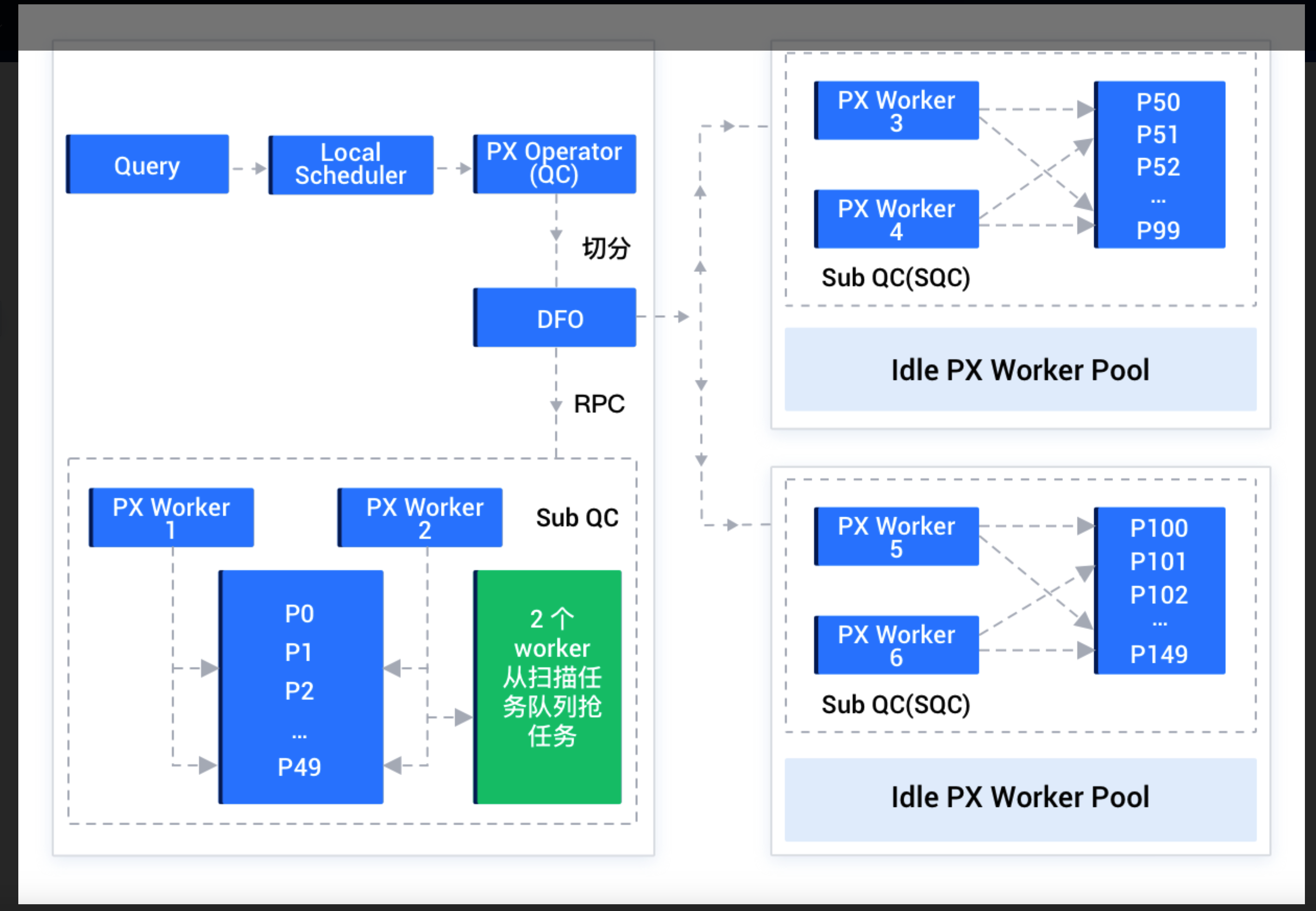
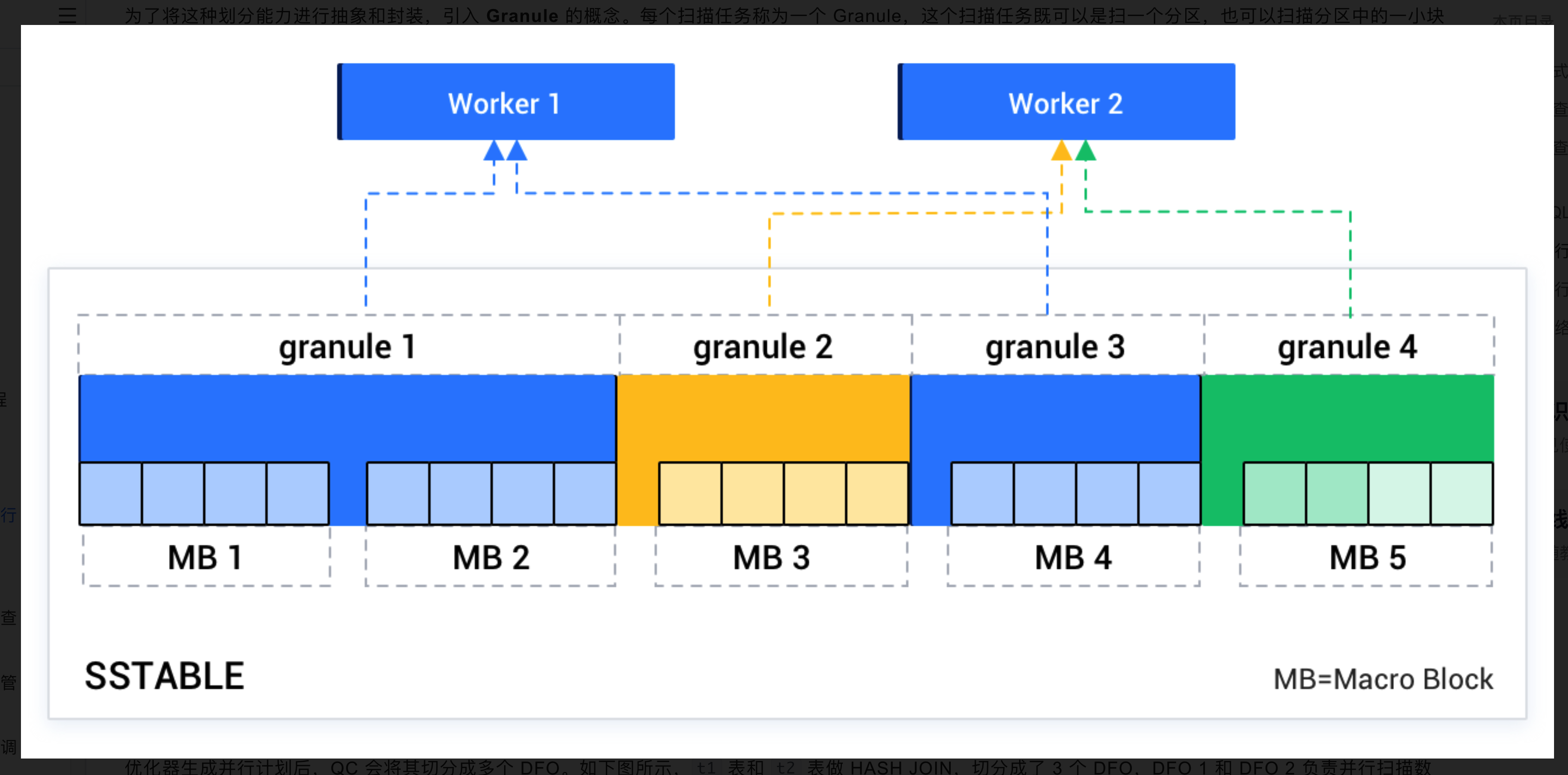
- 分区内并行
如果每个机器上分得的 Worker 数远大于分区数,会自动做分区内并行。每个分区会以宏块为边界切分成若干个扫描任务,由多个 Worker 争抢执行。
- 多表之前并行join
优化器生成并行计划后,QC 会将其切分成多个 DFO。如下图所示,t1 表和 t2 表做 HASH JOIN,切分成了 3 个 DFO,DFO 1 和 DFO 2 负责并行扫描数据,并将数据 HASH 到对应节点,DFO 3 负责做 HASH JOIN,并将最终的 HASH 结果汇总到 QC。
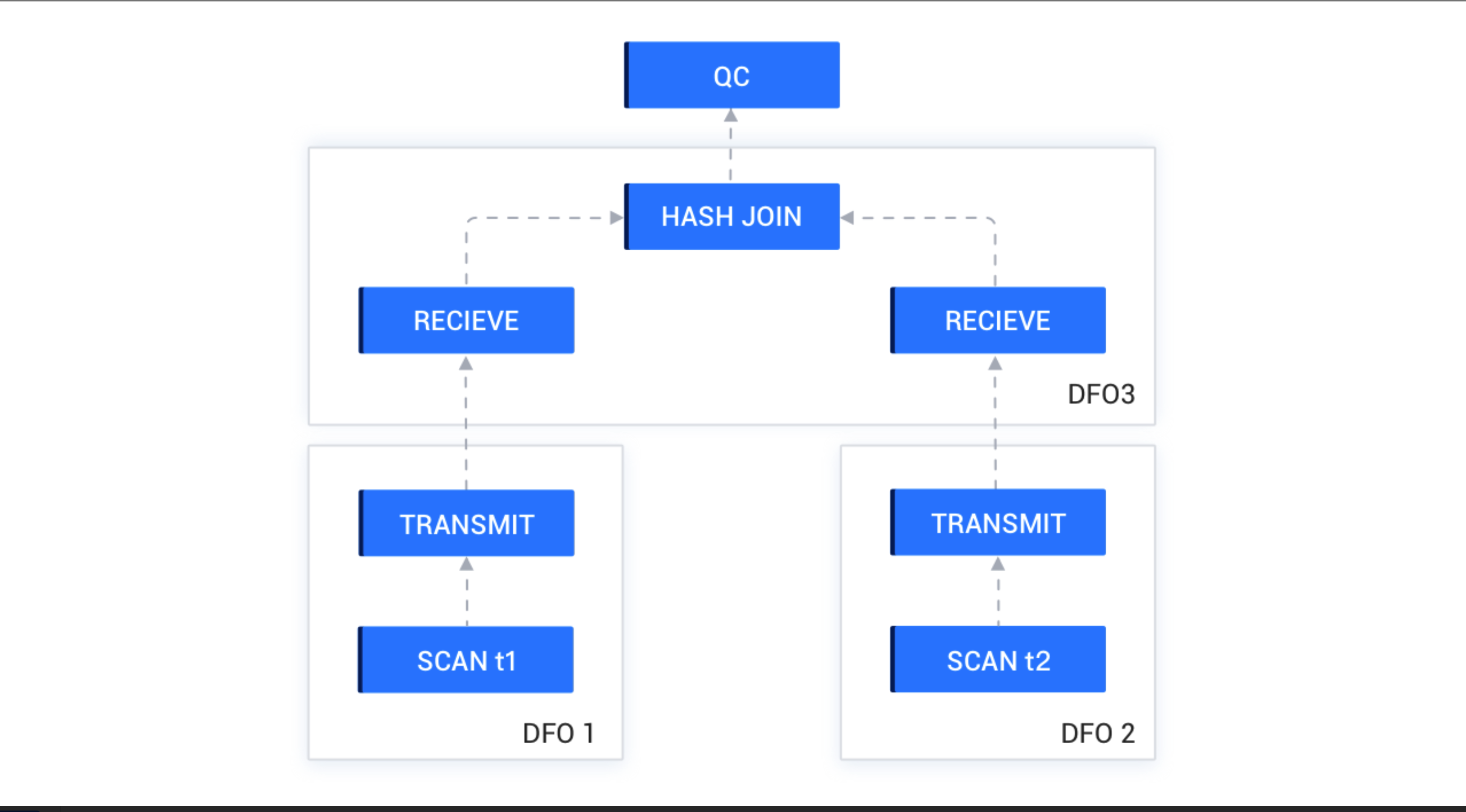
- QC 首先会调度 DFO 1 和 DFO 3,DFO 1 开始执行后就开始扫数据,并吐给 DFO 3。
- DFO 3 开始执行后,首先会阻塞在 HASH JOIN 创建 Hash Table 的步骤上,也就是会一直会从 DFO 1 收集数据,直到全部收集完成,建立 Hash Table 完成。然后 DFO 3 会从右边的 DFO 2 收集数据。这时候 DFO 2 还没有被调度起来,所以 DFO 3 会等待在收数据的流程上。DFO 1 在把数据都发送给 DFO 3 后就可以让出线程资源退出了。
- 调度器回收了 DFO 1 的线程资源后,立即会调度 DFO 2。
- DFO 2 开始运行后就开始发送数据给 DFO 3,DFO 3 每收到一行 DFO 2 的数据就回到 Hash Table 中查表,如果命中,就会立即向上输出给 QC,QC 负责将结果输出给客户端。
分区表并行查询
针对分区表的查询,如果查询的目标分区数大于 1,系统会自动启用并行查询,并行度 DOP 值由系统默认指定为 1。
如果 OceanBase 集群一共有 3 个 OBServer,表
ptable的 16 个分区分散在 3 个 OBServer 中,那么每一个 OBServer 都会启动一个工作线程(Worker Thread)来执行分区数据的扫描工作,一共需要启动 3 个工作线程来执行表的扫描工作。
非分区表并行查询
非分区表本质上是只有 1 个分区的分区表,因此针对非分区表的查询,只能通过添加 PARALLEL Hint 的方式启动分区内并行查询,否则不会启动并行查询。
分布式执行计划
分布式执行计划可以使用 Hint 管理,以提高 SQL 查询性能。
分布式执行框架支持的 Hint 包括 ORDERED、LEADING、USE_NL、USE_HASH 和 USE_MERGE 等。
- 案例网址
https://www.oceanbase.com/docs/enterprise-oceanbase-database-cn-1000000001576851